プログラムの実行中に,データ(領域)が増減したり, データ間の関係が動的に変化するような構造を表すために, 「連結リスト構造」や「木構造」と呼ばれるデータ構造が使われる.
ここではあまり深入りはしないが, そのような動的なデータ構造をC言語上で表現するには, 「ポインタ」と「構造体」が使われる.
このポインタは, 演習の第1回で分類したポインタの役割の中の 4. データ構造を実現する要素としてのポインタである.
一方,構造体は,そのようなデータ構造の構成要素(ノード)を表現するために用いる. 1つの要素は,その要素自身が持つデータと,他の要素を指すポインタよりなる. したがって,自分自身を指すポインタをメンバに含む構造体を用意する必要がある. このような構造体のことを「自己参照構造体」という.
typedef struct タグ名 型名;
struct タグ名 {
struct タグ名 メンバ名1;
struct タグ名 メンバ名2;
.....
型名 メンバ名n;
型名 メンバ名(n+1);
};
typedef struct タグ名 {
struct タグ名 メンバ名1;
struct タグ名 メンバ名2;
.....
型名 メンバ名n;
型名 メンバ名(n+1);
} 型名;
最も単純な連結リストとして,単方向リストを使ったプログラムを紹介する.
指定されたファイルの内容を読み, その中から「単語」(A〜Zとa〜zのみが連続した文字列と定義する)を切り出し, その出現回数を数える.ファイルにどのような文字列がどれぐらい含まれているかは, あらかじめ知ることができない. そのような場合にも,メモリが確保できる限り頻度表を拡張し, しかも文字コード順を保つように並べる.
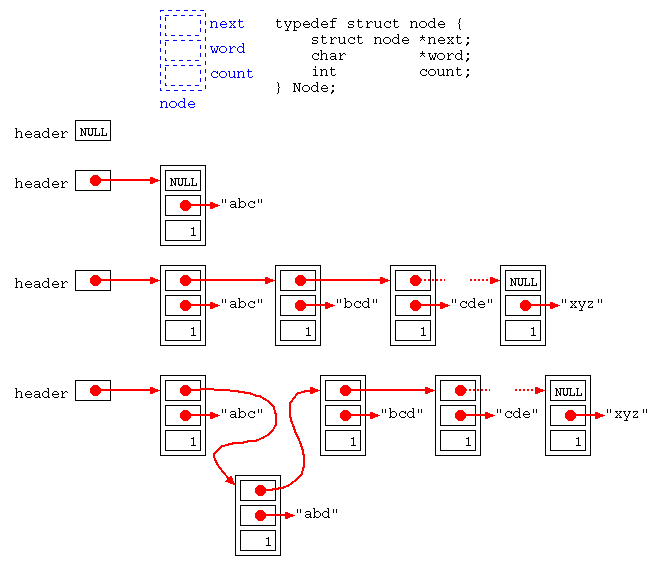
一つのノードが,1つの単語とその頻度に対応する.
typedef struct node {
struct node *next; /* 次のノードを指すポインタ */
char *word; /* 文字列を指すポインタ */
int count; /* 単語数を数える変数 */
} Node;
文字列が与えられる度に,リストを先頭から走査し,同じ文字列が見つかれば, そのノードの頻度を1増加させ,見つからなければ, 文字コード順の適切な位置に新たなノードを挿入する. 新たなノードを追加する際には,malloc()を使って, ノードと文字列を格納する領域を確保する.
ポインタ変数headerは,常にそのリストの先頭を指すようにしている.